AI agents now operate with extensive system access—reading files, executing commands, and querying production databases through MCP tools. Without structured observability, organizations cannot see what agents access, trace their reasoning, or control their actions. Traditional application performance monitoring answers "Is it up?" but AI agent observability must answer a fundamentally different question: "Is it thinking correctly?" The MCP Gateway addresses this gap by providing centralized governance, audit logging, and real-time monitoring across all MCP connections.
This article outlines the five-layer framework for AI agent observability, from foundational LLM traces through compliance reporting, with actionable implementation guidance for enterprise teams managing AI tool deployments at scale.
Key Takeaways
- Teams with comprehensive observability achieve 2.2x better reliability compared to those without structured monitoring
- The 11-20 agent threshold marks the point where manual debugging becomes unsustainable—requiring automated observability systems
- Observability investments are often justified through faster debugging, fewer production incidents, and tighter cost control
- Structured tracing and evaluation help teams identify and reduce production failures earlier than ad-hoc logging
- Luna-2 SLMs reduce evaluation costs by 97% compared to GPT-4 while maintaining quality assessment accuracy
- OpenTelemetry semantic conventions for GenAI provide vendor-neutral instrumentation that can reduce integration friction across observability tools
- Complete audit trails require five interconnected layers: tracing, monitoring, evaluation, logging, and governance
Unpacking the Observability Stack: From LLM Traces to Full-Stack Visibility
Unlike traditional software that follows deterministic execution paths, AI agents make probabilistic decisions at runtime. A single user query might trigger multiple LLM calls, tool invocations, and reasoning steps—each representing a potential failure point. LLM tracing captures these hierarchical execution paths from user input through agent planning, tool calls, and final output.
What tracing captures:
- Spans: Individual operations (LLM call, tool invocation, database query) with timing and metadata
- Traces: Complete execution paths linking spans across the agent workflow
- Context propagation: Correlation IDs that connect operations across distributed services
- Token usage: Input/output token counts for cost attribution and optimization
The foundation layer answers "Where did it go wrong?" by creating a complete record of agent execution. When an agent produces incorrect output, traces reveal whether the failure occurred during retrieval, reasoning, or tool execution.
OpenTelemetry semantic conventions help standardize how GenAI systems capture traces, improving interoperability across observability platforms. This can reduce migration friction and make it easier to route telemetry across different backends.
The LLM Proxy monitors every MCP tool invocation, bash command, and file operation from coding agents, providing the foundational trace data required for enterprise observability.
Connecting LLM Calls to Infrastructure
Full-stack visibility extends beyond LLM interactions to encompass the complete agent architecture. Enterprise observability platforms connect traces to infrastructure metrics, enabling teams to correlate agent behavior with system performance.
Implementation approach:
- Add tracing decorators to agent functions
- Configure context propagation headers across microservices
- Define sampling strategies (100% for failures, 10-20% for successes)
- Tag traces with business context (user tier, feature flags, session IDs)
Bridging the Gap: Monitoring MCP Tool Invocations for Deeper Insight
LLM traces capture model interactions, but MCP tool monitoring extends visibility into the agent's actual interactions with external systems. When an agent queries a database, sends an email, or executes a shell command, tool invocation tracking captures the complete input/output sequence.
Critical tool call data:
- Tool selection: Which tools the agent chose and why
- Input parameters: Arguments passed to each tool
- Execution results: Success/failure status and response data
- Timing metrics: Latency for each tool call
This layer answers questions that LLM traces alone cannot: Did the agent call the right tool? Did it pass correct parameters? Did the tool return expected results?
Organizations deploying AI coding assistants like Cursor or Claude Code face particular risks. These agents execute bash commands, access files, and interact with production systems. The LLM Proxy's tool tracking monitors every operation, creating visibility into what files agents access and which MCPs are installed across engineering teams.
From LLM Output to Real-World Impact
Tool invocation monitoring bridges the gap between model reasoning and business outcomes. Practical evaluation systems track not just "agent ran successfully" but "customer got their issue resolved."
Monitoring dimensions:
- Task completion rates across different tool combinations
- Error patterns by tool type and user context
- Tool usage frequency and adoption trends
- Execution chains revealing common agent workflows
Securing the Enterprise Frontier: Real-time Data Access & Security Guardrails
Observability without security controls creates visibility into problems without the ability to prevent them.
Data access logging requirements:
- Who: User identity and role triggering the agent
- What: Specific data assets accessed (tables, documents, APIs)
- When: Timestamps with timezone normalization
- Why: Business context linking access to legitimate use cases
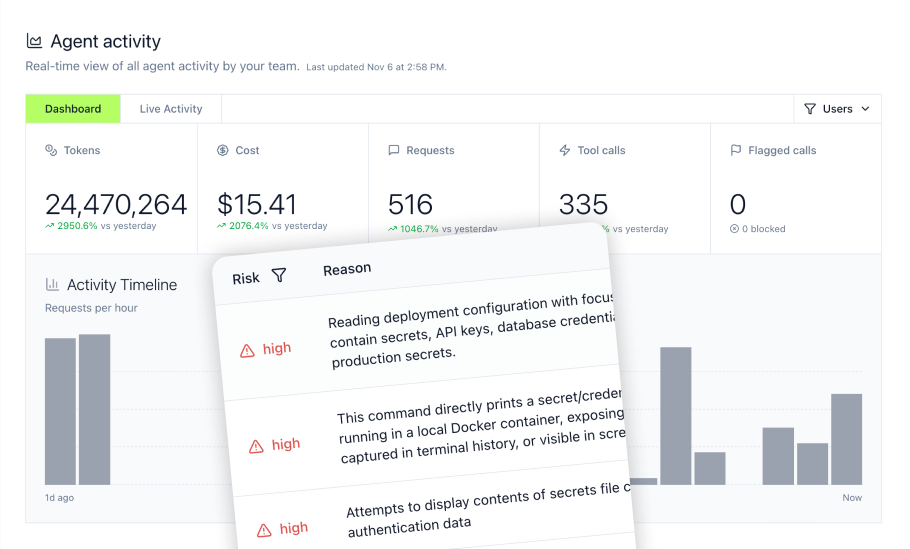
The LLM Proxy's security features block dangerous commands in real-time, protect sensitive files from access, and maintain complete audit trails. This prevents agents from reading .env files, SSH keys, credentials, and other sensitive configuration.
Implementing Proactive Protection
Runtime policy enforcement enables organizations to define what agents can and cannot do before deployment:
Guardrail categories:
- Command blocking: Prevent execution of destructive bash commands
- File access restrictions: Whitelist/blacklist patterns for sensitive paths
- Data egress controls: Block agents from sending data to unauthorized endpoints
- Rate limiting: Prevent runaway agent loops consuming excessive resources
Healthcare organizations using AI for clinical decision support often pair observability with faithfulness evaluators and human review to reduce hallucination risk and catch failures earlier.
For teams working with Claude or other AI assistants, the MCP data risk guide provides practical frameworks for managing data access across enterprise deployments.
Performance, Cost, and Usage: Optimizing AI Agent Operations
AI agents incur costs with every LLM call, and without visibility, token spend can grow unchecked. Cost analytics track spending per team, project, and tool with detailed breakdowns enabling optimization.
Key performance metrics:
- Latency: P50, P95, P99 response times across agent workflows
- Token usage: Input/output tokens by model, user, and task type
- Error rates: Failures by category (timeout, rate limit, model error)
- Cost per interaction: Total spend attributed to individual agent sessions
Teams deploying multi-agent chatbots often use observability data to identify expensive interaction patterns and optimize model routing.
The MCP Gateway provides real-time monitoring dashboards for server health, usage patterns, and security alerts—enabling teams to track performance across all MCP connections.
Driving Efficiency Through Measurement
Smaller specialized language models can reduce evaluation costs by up to 97% compared to GPT-4 while maintaining quality assessment accuracy. This enables organizations to evaluate 100% of agent interactions rather than sampling.
Optimization strategies:
- Route simple queries to smaller, cheaper models
- Cache frequent tool call results to reduce redundant operations
- Identify and eliminate unnecessary agent reasoning loops
- Set cost thresholds with automated alerts for anomalies
Teams using structured deployment approaches report significantly faster AI development cycles compared to ad-hoc implementations.
Building a Complete Audit Trail: The Backbone of Compliance Reporting
Regulators increasingly require organizations to explain AI decision-making. Audit trails transform operational observability data into compliance documentation by creating immutable records linking agent actions to business outcomes.
Audit trail components:
- Immutable logs: Tamper-proof records of every agent interaction
- PII redaction: Automatic masking of sensitive data before storage
- Retention policies: Configurable storage periods aligned to operational and compliance requirements
- Lineage tracking: Connection between agent outputs and source data
Financial services teams use complete audit trails to streamline audit preparation and make reviews easier to defend.
The MCP Gateway maintains complete audit logs of every MCP interaction, access request, and configuration change—essential for SOC 2 Type II evidence collection and GDPR-aligned governance.
Automating Compliance Reporting
Enterprise observability platforms generate compliance reports automatically from collected trace data:
- SOC 2 Type II evidence to support access control and audit reviews
- Healthcare-oriented audit evidence for teams with medical or regulated workflows
- GDPR data processing records with subject access support
- Custom regulatory reports for industry-specific requirements
Standardizing AI Agent Deployments: The Role of Centralized Governance
As organizations scale from 5 to 50+ agents, centralized governance becomes essential for maintaining consistency. Decentralized deployments create security gaps, compliance blind spots, and operational inefficiencies.
Governance capabilities:
- Unified authentication: OAuth 2.0, SAML, and SSO integration across all agents
- Role-based access control: Define who can use which tools and access what data
- Policy enforcement: Automatically apply security and usage policies
- Rate control: Prevent individual users or teams from monopolizing resources
The MCP Gateway provides centralized governance with unified authentication, audit logging, and rate control for all MCP connections. It supports both shared service accounts and per-user OAuth flows with granular tool access by role.
Scaling AI Responsibly
Research shows that organizations crossing the 11-20 agent threshold without governance infrastructure experience significantly higher incident rates. Governance frameworks should be implemented before reaching this scale.
Governance checklist:
- Centralized credential management for all AI tool API keys
- Standardized deployment patterns with pre-configured policies
- Cross-team visibility into tool usage and data access
- Automated policy verification during agent onboarding
The Journey to Sanctioned AI: Turning Shadow AI into Strategic Advantage
Shadow AI continues to grow as employees adopt AI tools without IT oversight. Without governance, these deployments create security vulnerabilities, compliance violations, and operational risks.
Shadow AI risks:
- Sensitive data shared with unauthorized AI services
- Inconsistent security controls across ad-hoc deployments
- No audit trails for regulatory compliance
- Duplicated costs across redundant tools
Transforming shadow AI into sanctioned AI requires balancing security with accessibility. Organizations with formal AI strategies tend to outperform unstructured adoption because they standardize controls, ownership, and review processes earlier.
Sanctioning approach:
- Inventory existing AI tool usage across the organization
- Assess security and compliance requirements by use case
- Deploy approved tools with appropriate guardrails
- Provide self-service access through governed channels
The enterprise AI governance whitepaper outlines a 3-phase implementation roadmap with metrics for turning unsanctioned AI into strategic capability.
Building Your Observability Strategy: A Phased Implementation Roadmap
Implementing comprehensive observability requires phased deployment rather than attempting all five layers simultaneously.
Phase 1: Foundation (Weeks 1-4)
- Instrument agent frameworks with tracing decorators
- Configure basic trace capture and context propagation
- Set up dashboards for latency, error rates, and token usage
- Implement PII redaction before production deployment
Phase 2: Quality & Security (Weeks 4-8)
- Deploy automated evaluators for task completion and hallucination detection
- Configure security guardrails for file access and command execution
- Create golden datasets for quality benchmarking
- Set up alerting for quality degradation and security anomalies
Phase 3: Governance & Compliance (Weeks 8-12)
- Connect traces to data assets for lineage tracking
- Implement RBAC for observability dashboard access
- Configure audit log retention per compliance requirements
- Generate automated compliance reports
Enterprise teams often justify observability investments through reduced debugging time, fewer production incidents, and better AI spend control, though results vary by implementation.
Measuring Success
Key metrics to track:
- Time to debug agent issues (target: 50%+ reduction)
- Production incident frequency (target: 60-80% reduction)
- Cost per agent interaction (target: 40%+ optimization)
- Compliance audit preparation time (target: 80%+ reduction)
Teams looking to get started with Claude-based workflows should review the Claude skills guide for practical implementation patterns that integrate with enterprise observability requirements.
MintMCP: Production-Ready AI Agent Observability
Organizations deploying AI agents at scale need observability infrastructure that balances developer velocity with enterprise governance. MintMCP provides a unified platform spanning foundational tracing, governance, and compliance reporting without requiring teams to stitch together as many point solutions.
Why teams choose MintMCP:
The MCP Gateway delivers centralized governance for all MCP connections with unified authentication, role-based access control, and complete audit trails. Teams gain real-time visibility into which agents are accessing what data, with automatic policy enforcement preventing unauthorized operations before they execute.
The LLM Proxy monitors every tool invocation, bash command, and file operation from AI coding assistants. Security guardrails block dangerous commands in real-time while comprehensive logging captures the complete context needed for debugging and compliance.
Enterprise-grade features:
- SOC 2 Type II attestation ensures MintMCP meets enterprise security requirements for audit controls, access management, and data protection
- Per-user OAuth flows enable fine-grained access control where each engineer's AI agent operates with their individual permissions rather than shared service accounts
- Complete audit trails link every agent action to user identity, business context, and data lineage—essential for regulatory reviews and security investigations
- Real-time monitoring dashboards surface server health, usage patterns, and security alerts across MCP connections in one centralized view
Unlike point solutions that address only tracing or only security, MintMCP integrates all five observability layers into a unified platform. This eliminates integration complexity while providing the comprehensive visibility enterprises need to deploy AI agents responsibly at scale.
For teams deploying AI agents in production, this kind of centralized observability can support faster incident review, more consistent compliance workflows, and stronger operational confidence. The platform supports both STDIO servers deployed on managed infrastructure and remote MCP servers, giving organizations flexibility in their deployment architecture.
Frequently Asked Questions
What distinguishes AI agent observability from traditional APM tools?
Traditional application performance monitoring tracks deterministic software behavior—request/response cycles, database queries, and service health. AI agent observability addresses non-deterministic systems where the same input may produce different outputs based on model reasoning. It captures not just "what happened" but "why did the agent decide this," including reasoning chains, tool selection logic, and quality metrics like hallucination rates. APM tells you if your system is running; AI observability tells you if your agent is thinking correctly.
How should organizations handle PII in agent traces?
Implement automatic PII redaction at the instrumentation layer, before data reaches your observability platform. Libraries like llm-guard detect and mask sensitive data patterns including email addresses, phone numbers, and government IDs. Configure redaction rules specific to your domain—healthcare systems need different patterns than financial services. Store unredacted data only when legally required and with appropriate access controls. For most operational observability, redacted traces provide sufficient debugging capability while reducing compliance risk.
What sampling strategy balances cost with visibility?
Sample 100% of failures and edge cases—these represent the highest-value learning opportunities. For successful interactions, 10-20% sampling typically provides statistical significance for trend analysis while controlling storage costs. Adjust sampling based on user tier (100% for enterprise customers, lower for free tier) and interaction risk level (100% for high-stakes decisions). Dynamic sampling that increases rates during anomalies captures more data when it matters most. Avoid uniform low sampling rates that may miss critical patterns.
How do multi-agent systems change observability requirements?
Multi-agent systems require correlation across agent handoffs, tracking which agent made which decision and how information flowed between them. Each agent-to-agent communication becomes a span in your trace, with context propagation ensuring you can follow a request through the complete workflow. Visualization tools that render multi-agent traces as directed graphs help teams understand complex coordination patterns. Without this correlation, debugging becomes exponentially harder as agent count increases.
When should organizations transition from open-source to commercial observability platforms?
Open-source tools like Langfuse and Arize Phoenix work well for initial deployment and validation. Transition to commercial platforms when: compliance requirements demand SOC 2 Type II attestation or healthcare-related security and audit controls that are difficult to manage yourself; multi-team access control becomes critical; you need dedicated support SLAs for production systems; or trace volume exceeds what your team can self-host economically. The 11-20 agent threshold often coincides with these requirements, making it a natural evaluation point for platform upgrades.